
速盈注册
Orca: A Modular Query Optimizer Architecture for Big Data
发布时间:2024-03-11 13:08:57 浏览次数:
在之前的几片paper笔记中,对最为主流的两套优化器框架进行了解读,包括bottom-up dynamic programming的search策略和基于Top-down memorization的search策略,文章通道:
System-R:
https://zhuanlan.zhihu.com/p/364303913Volcano / Cascades
https://zhuanlan.zhihu.com/p/364619893https://zhuanlan.zhihu.com/p/365085770从上面这3个命名就能看出来,第一套框架是有System-R这个实际的实现系统的,虽然它是IBM research lab中的实验性项目,并没有做到商业化,但从论文的描述中,还是可以清晰的捋出实现脉络,比较简单易懂,易于指导工程实践(目前PolarDB 并行优化器的设计,也参考了DP-based的思路)。
但Volcano/Cascades的论文内容则要抽象和艰深的多,原作者Graefe在paper中提及到Volcano项目也只是一个学术性的原型系统,没有一个著名的系统为其背书(当然,Graefe在2000年前后去了MicrosoftSQL并主导了SQL Server查询优化器的整个重新设计和实现)。相信很多人和我一样,在看完论文甚至一些的导读文章后,也无法很好的将这个框架与工程实现映射起来,而在读完Orca这篇paper,相信可以帮助我们更好的理解cascades这个牛叉的框架。
Orca是Pivotal公司基于Cascades框架自研的一套独立的查询优化器服务,主要服务于Pivotal公司的另外两个系统:基于Hadoop的HAWQ和著名的Greenplum,阿里的大数据分析引擎Hologres也是用Orca作为其优化器。从这里也可以看出,复杂的Cascades框架,确实具有更加的复杂查询处理能力,因此更适合于大数据或数仓类型的产品。其基本特点有4个:
- 模块化,以独立的Service形态单独存在,并不依附于特定的数据库产品,对外是标准化的接口和协议([1]),这样理论上可以被集成到任何数据库系统中。
- 扩展性,可以扩展新的operator/cost model/property/rules
- 支持并行优化,其自身实现了subtask和job scheduler
- 可验证性,实现了方便测试与debug的工具集,便于复现问题 + debug或者test,也便于快速迭代新功能
- 作为一个standalone服务单独存在是Orca比较有趣的一点,其基本流程
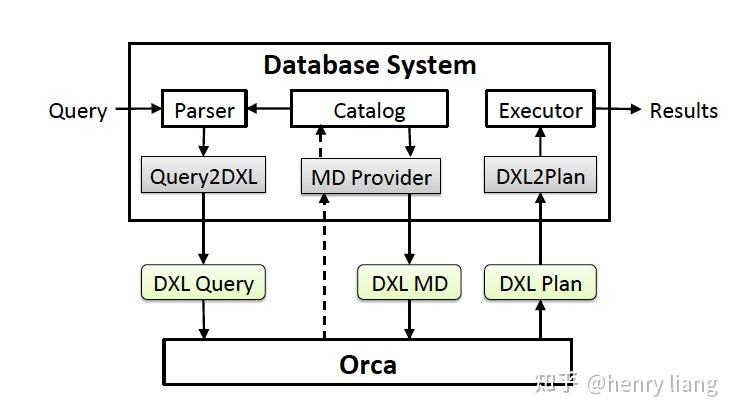
- Query进入DB后,要经过parser转换为AST,然后通过Query2DXL这个模块,将AST描述为DXL可以表述的标准形式(DXL Query)
- Orca接收到query后开始优化,在过程中会获取必要的元信息(如表/列的schema信息,统计信息等),这通过MD Provider实现,并转换为DXL MD传递给Orca,Orca内部是有MD cache的,来避免频繁获取metadata,metadata维护一个version信息,来判断是否过时。
- Orca完成优化流程,确定最优plan后,以DXL Plan的形式,传递给DB端,DB端使用DXL2Plan这个模块转换为内部可识别的physical plan,交由Executor执行。
可以看到Query2DXL,MD Provider,DXL2Plan这3个模块构成了适配层,不同的DB侧只需要根据自身特点完成转换工作即可。但个人感觉这个过程还是有些重,DXL(XML)本身就是复杂而臃肿的协议,query/plan的复杂性、metadata的维护都还是有一定工程挑战的。
Orca的整体框架和各个组件如下
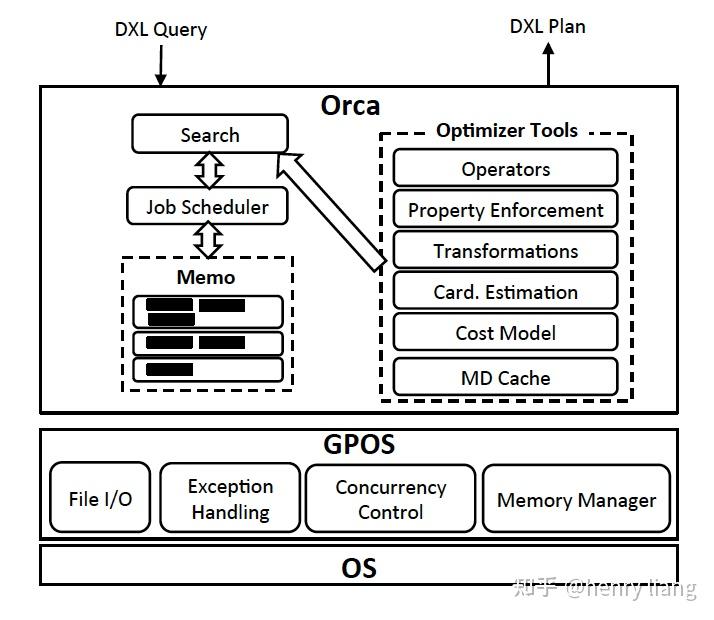
1. Memo : Cascades中的概念,是整个搜索空间的全局容器,代表逻辑等价类Group,表达式 Expr,都包含在其中,内部通过一些机制来实现高效的结构重用,减少内存开销。
2. Search + Job Scheduler,表示具体的算法流程和执行优化的任务调度,和Cascades的paper一样,它把优化任务拆分为subtask。Search的整体过程和Cascades paper中虽然没有完全对齐,但基本思路是一致的:
exploration进行逻辑变换 <-> implementation完成物理算法选择 -> 递归到下层继续优化。
3. Transformation : 这里包括logical + physical的转换,每个rule,都是可以单独开/关的。可以看到,Orca中的transformation,既包含逻辑等价变换,也包含选择物理算子,而它的exploration则是纯粹的等价变换,为了便于区分,我们还是使用exploration来表示逻辑变换,而使用implementation表示选择物理执行算法。
4. Property Enforcement : property的描述是规范且可扩展的,可以具有不同类型,paper中列举了logical property(输出哪些columns),physical property(数据的有序性,分布情况)+ scalar property(join columns,这里猜测是和property有关??)。
这里的property和Cascades中的概念完全一致,在上层算子确定物理执行方式的同时,会对下层产生某种对输入数据的物理属性要求(e.g sort merge join要求数据在join key上有序),下层算子可以自身来保证满足这种物理属性要求(e.g index scan提供有序性)或者利用Enforcer来保证(e.g 加入sorting操作)。
5. Metadata Cache缓存在Orca侧,metadata通过version number来判断是否失效,这样下次再获取meta时可以先验证version信息,如果已过期再获取新数据,避免过多大量信息交互。
paper中使用了一个简单SQL 来示例优化流程:
SELECT T1.a FROM T1, T2
WHERE T1.a=T2.b
ORDER BY T1.a;数据是sharding的,T1 基于Hash(T1.a)分布,T2基于Hash(T2.a)分布。这个plan的初始状态是
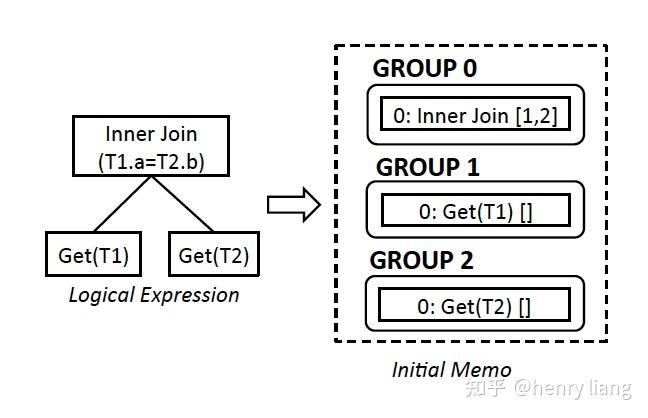
可以看到,自顶向下,每个group描述一个逻辑操作,上层group 0中通过编号1,2引用了下层group。每个group内的编号0,是初始的expr。
1. Exploration:
在group内,基于已有expr做logical transformation,这里可能会生成新的expr,在本例中可以通过join交换律从 Inner join[1,2]=> Inner join[2,1]。如果逻辑变换较大,则可能生成新的group,例如执行view merge操作展开内层表到外层,就会出现作为外层表的多个table group。
从论文中的描述,感觉exploration是集中完成的,而没有和implentation交错执行,估计交错方式实现复杂度太高。
2. Statistics Derivation:
在完成exploration后,就可能建立起由逻辑等价类(group)组成的多棵候选的plan tree。在开始搜索物理plan之前,先要有必要的统计信息才可以计算相关的代价,因此有一个收集+生成统计信息的过程。在Orca中,这个统计信息主要就是指一系列的column histograms,用它来做Cardinality Estimation和检测data skew。
这里针对每个group的statistics,提出了一个非常有趣的概念:[2],Statistics promise。我们都知道统计信息都是不精确的,那么在同一个逻辑表达式上,也许有多个统计信息可以使用,可以尽量选择置信度高的统计信息用于估算。例如一个group中,可能有多个表示inner join的等价group expr,其中1种join组合方式,涉及的join condition较少,而另一种join组合方式的join condition则更多(不同join order),这时选择更少condition的可能误差就会更少(cardinality estimation的误差会随着乘积传播和扩大)。
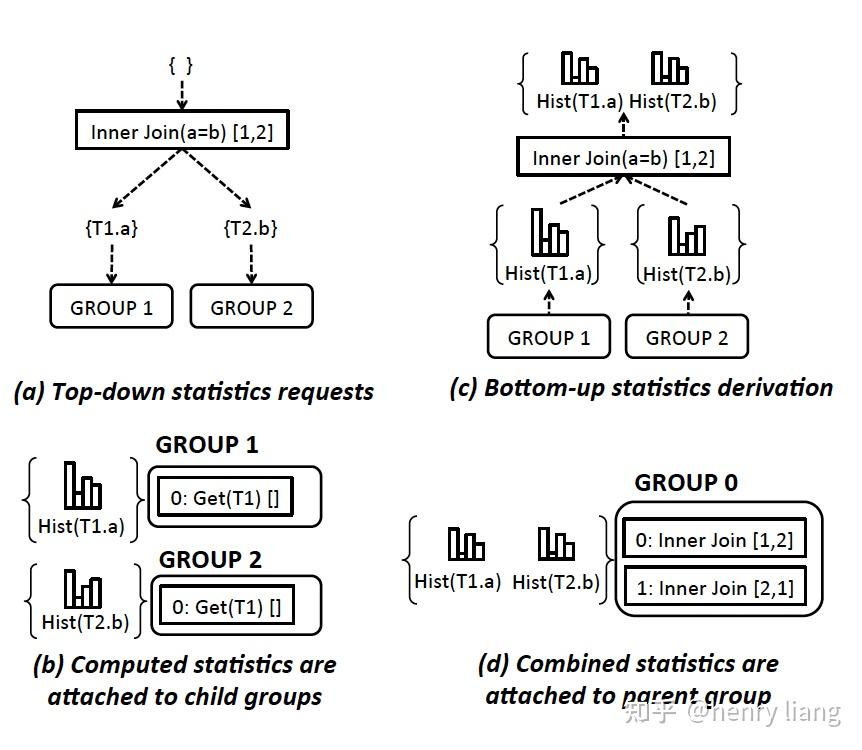
对各个group,自底向上完成,histogram的估算有很多方法,例如SQL Server中的方法:
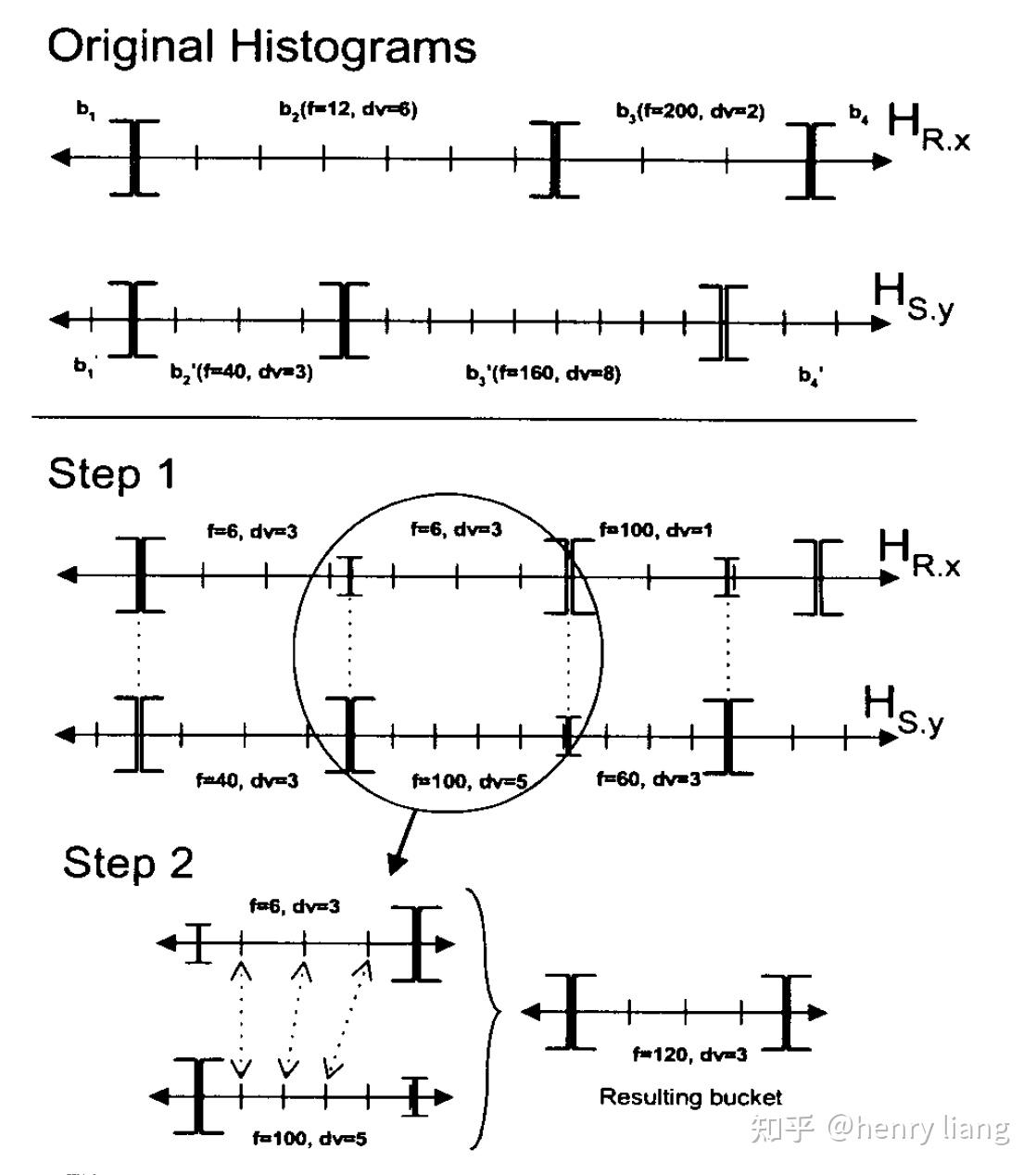
上图并不难理解,根据join两侧的column histogram,获取两个domain中的bucket boundaries集合,等于将两个histogram都切分成了更小的sub bucket,在每个sub bucket内仍假设均匀分布,并基于join inclusion的假设来计算join cardinality,再累计起来,就得到了join group expr的histogram。
3. Implementation:
为每个logical group expr,选择所有可能使用的物理实现算法,包括scan方式,join算法等,生成对应的physical group expr。
4. Optimization:
Search plan space,过程中会计算相应cost。初始会从root group开始,根据一个optimization goal(cost limit , property requirement),对一个group开始优化,等同于从这个group开始,选出其内部最优的physical expr以及其下层整个physical expr tree。
在一个group内,会从每个step 3生成的每个physical expr为起点深度优先,向下查找,首先会扣除它自身的cost,并根据其上层的property requirement以及expr自身的property特性,形成对其输入group的physical property要求,这样就从当前level 1 的(cost , prop requirement1) 递归到了下层group (level 2),optimization goal变为了 (cost - l1 cost, prop requirement2)。
对每个physical expr来说,如果所属group的optimization goal中的property requirement可以被expr本身输出的物理属性所满足,则可以直接应用该expr,否则需要加入enforcer来强制目标属性,下图中给出了一个简单的inner hash join的优化过程:
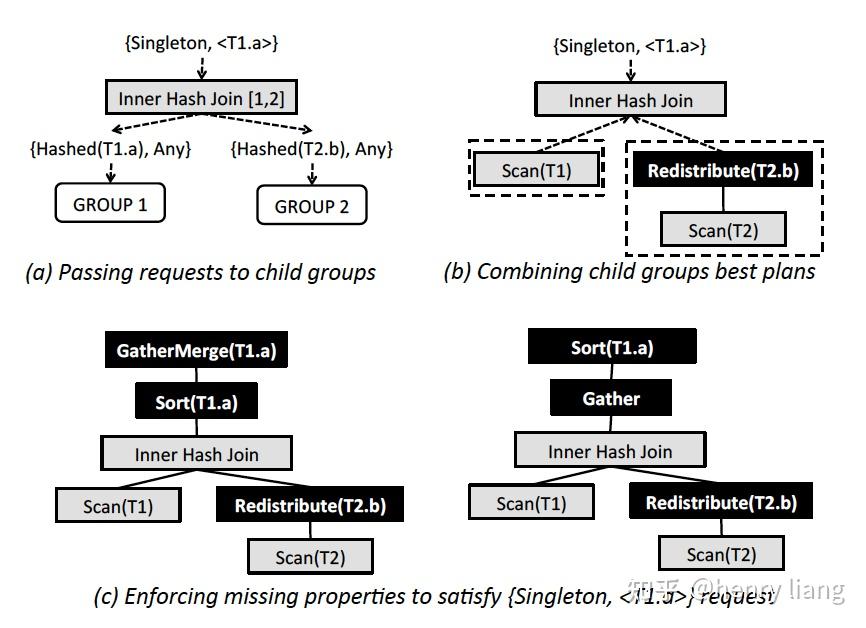
图(a)中,初始的optimization goal施加在group 0上,它要求输出数据在单个节点中(singleton),且按照T1.a有序。当进入group内处理每个physical expr时(本图中是Inner hash join[1,2]这个expr),会结合inner hash join的特点,生成对children group的optimization goal,这里分别是左右child的 Hash(join key), 顺序则是Any,也就是说,要求左右table数据都分布在join key上,且由于hash join不保序,因此其children也不要求输出有序。
图(b)中,假设T1的数据已经在T1.a列上分布,而T2的分布键却不是T2.b,因此无法满足Hash(T2.b)这个物理属性,需要加入Redistribution(T2.b)这个enforcer来满足分布要求。
图(c,d)中,inner hash join已经在各个节点上完成了co-located join,但数据并不满足singleton的要求,也不满足有序的要求,这时需要加入新的enforcer,那么有两种选择:
要么如图c中,先在各节点排序后在汇总到leader节点,即sort -> gather -> mergesort。
要么如图d中,先gather到leader节点,再对全量数据排序。
选哪种方案,就取决于cardinality 和 cost了。
5. Memo
Memo中高效的组织了Group、Group Expr的信息,使其可以被复用,具体来说
每个group维护一个hash table,保存{property request -> 本group最优physical group expr}的映射。
每个group expr维护一个local hash table,保存(property request -> 各个input的property request)的映射。
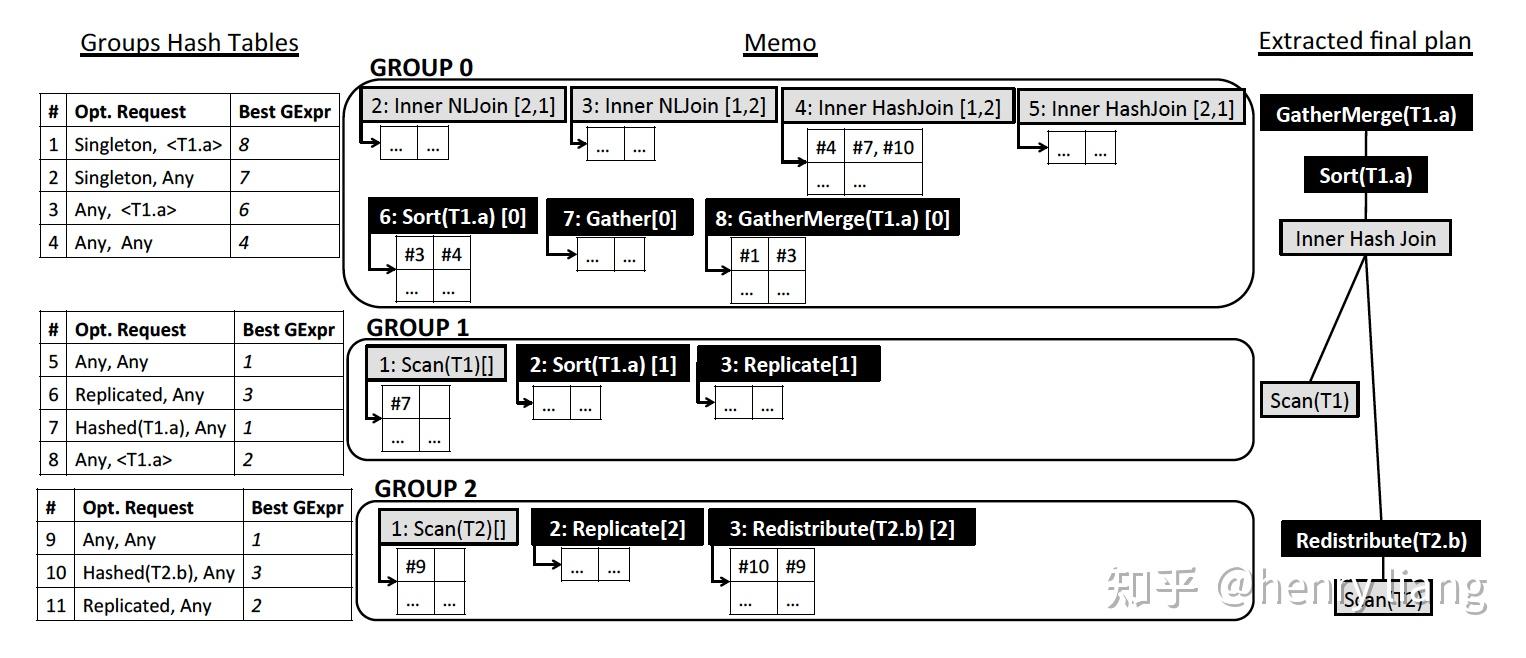
上图中是一个比较完整的Memo结构,其中灰色方框的是physical group expr,黑色方框则是enforcer。每个group左侧的table就是 request -> best expr,每个expr下方的小表格,则是property request(表格第一列) -> input children(表格第二列)。
这样首先同一个expr/enforcer,可以以编号的形式被多个其他expr引用,从而实现了结构的复用最小化内存占用。如果想要获取最优expr tree,只需要顺着root group request -> group hash -> group内最优expr -> expr local hash -> children group request -> ...的方式,串连起整个expr/enforcer tree。
6. Metadata exchange
MD 获取的设计提前其作为外挂优化器的灵活性:
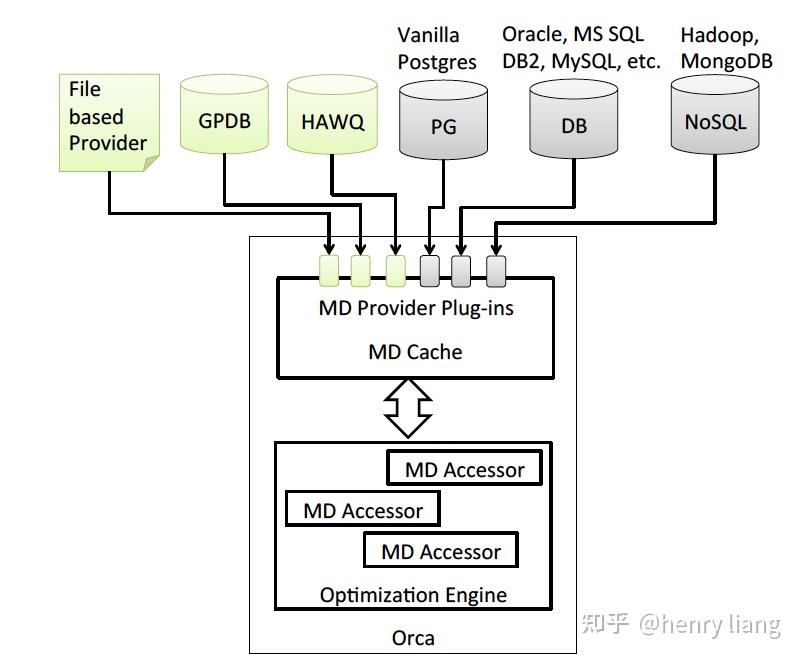
不同的外部系统,都可以基于MD Provider提供适配的元数据,元数据会在优化期间保存在MD Cache中,优化结束后可以释放,有个有趣的地方是最左侧的File based Provider,也就是说Orca可以完全不依赖于一个在线系统,这种用local file来mock一个DB的方式,使得Orca可以被更好的测试、调试和验证。
7. 可验证性
优化器可以说是数据库系统中最为复杂和不确定性的组件,在漫长的开发流程中,高效的验证能力,快速发现regression,快速定位问题是保证开发效率以及解决线上问题的必要条件。因此围绕Orca,引入了两个工具:
- AMPERe
当Orca的执行中出现错误,或选中了次优计划时,可以将能够复现问题的最小化环境dump下来,包括query + metadata + config + stack backtrace等,并序列化为DXL的形式,这样后续可以脱离线上系统,以本地DXL文件的形式重新导入Orca,重建问题环境来调试。这和core dump的思路类似。
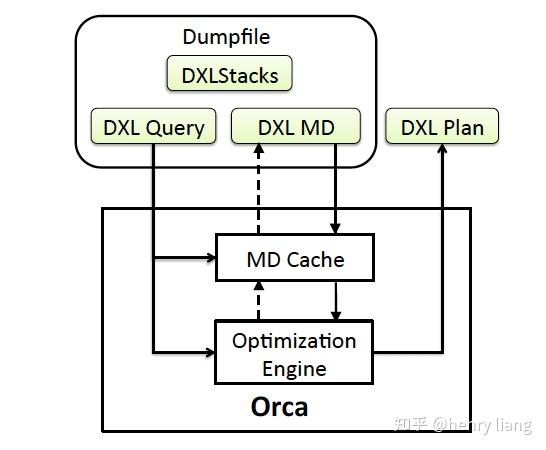
- TAQO
用来针对optimizer中的cost model进行测试,来衡量一个optimizer对于最优计划的选择能力。其思路其实很简单直接,优化器的本质就是根据计算出的cost,作为执行时间的衡量标准来对alternative plans进行排序,理想情况下最低cost对应的就是最优plan,因此其是否精确,可以用optimizer对于plan的正确排序能力来衡量。
当评估一个cost model时,我们可以从Memo的plan space中,选出若干候选plan(如下图p1 p2 p3 p4) ,观察其cost评估值c与其实际的执行时间a,这样就形成了一对序列(c1, c2 ... cn) + (a1, a2 ... an)。如果是完美的优化器,应该是c序列的顺序,与a序列的顺序完全一致,也就是说cost的顺序就是实际的执行时间顺序,基于这个原则,我们可以用2个序列的顺序相关性,来对目标cost model进行打分,选择相关度最高的cost model。
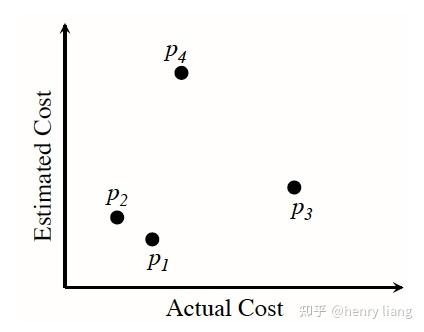
这个测试机制的强大之处在于,它可以不用调整optimizer的细节,基本把它当做黑盒,不绑定在特定的host系统,也不需要做复杂的profiling,易于实现。如果有同学需要评估自己优化器的代价模型,这是个很值得参考的方案。当然还有一些细节,Pivotal也专门写了篇paper介绍TAQO,我在
https://zhuanlan.zhihu.com/p/365621518中做了详细介绍。
相信看完这篇文章,大家能对Cascades框架有更直观的体感。其高度的灵活性和扩展性使其可以更好的扩展search space,更可能选中最优plan,但也导致了search成本更高,时间更长。orca本身也在做一种multi-stage的优化方式,每个stage有cost + 优化时间 + rule subset的限制,在资源不多或要求不高的情况下,就可以得到一个不错的plan。这和SQL Server的思路大致相同。
地址:海南省海口市58号 电话:0898-88889999 手机:13988888888
Copyright © 2012-2018 首页-速盈娱乐-注册登录站 ICP备案编号:琼ICP备88889999号


 88889999
88889999

