
速盈注册
SMO算法是干什么的?有什么作用?不要纯概念
发布时间:2024-04-22 14:36:59 浏览次数:
wiki:
https://en.wikipedia.org/wiki/Sequential_minimal_optimization最近刚看完smo算法的代码,所以试着回答题主的问题。
解决svm首先将原始问题转化到对偶问题,而对偶问题则是一个凸二次规划问题,理论上你用任何一个解决凸二次规划的软件包都可以解决,但是这样通常来说很慢,大数据情况下尤其不实际,smo是微软研究院的大神发明的解决svm对偶问题的优化算法,可以更快找到好的解。通常而言分简化版和优化版smo算法。
简化版:每次迭代随机选取alpha_i和alpha_j,当然其中要有一个违反kkt条件,通常先选一个违反kkt条件的alpha_i,然后随机选择一个alpha_j,然后用类似坐标上升(下降)的算法来优化目标函数,具体细节题主可以看相关代码,推荐《machine learning in action》的svm部分,但是这样的优化方式并不是最快的;
优化版:用启发式的算法选择alpha_j,即选择alpha_j,使得|Ei-Ej|最大,至于为什么,因为变量的更新步长正比于|Ei-Ej|,也就是说我们希望变量更新速度更快,其余的和简化版其实区别不大;
应该还有其他版本的smo,没看过不做评论,希望对题主有用。
SMO(Sequential Minimal Optimization)是针对求解SVM问题的Lagrange对偶问题,一个二次规划式,开发的高效算法。传统的二次规划算法的计算开销正比于训练集的规模,而SMO基于问题本身的特性(KKT条件约束)对这个特殊的二次规划问题的求解过程进行优化。对偶问题中我们最后求解的变量只有Lagrange乘子向量,这个算法的基本思想就是每次都只选取一对
,固定
向量其他维度的元素的值,然后进行优化,直至收敛。
SMO干了什么?
首先,整个对偶问题的二次规划表达如下:
SMO在整个二次规划的过程中也没干别的,总共干了两件事:
- 选取一对参数
- 固定
向量的其他参数,将
代入上述表达式进行求最优解获得更新后的
SMO不断执行这两个步骤直至收敛。
因为有约束存在,实际上
和
的关系也可以确定。
这两个参数的和或者差是一个常数。
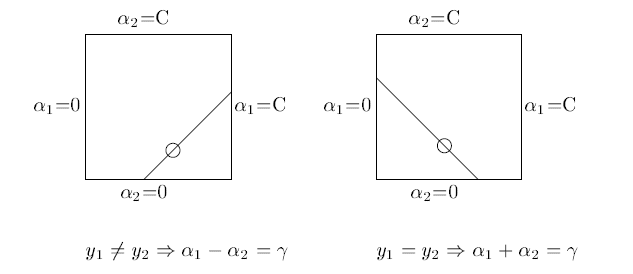
所以虽然宣传上说是选择了一对,但还是选择了其中一个,将另一个写作关于它的表达式代入目标函数求解。
为什么SMO跑的那么快,比提出之前的算法不知道高到哪里去了?
正如上面提到的,在固定其他参数以后,这就是一个单变量二次规划问题,仅有的约束也是这个变量,显然有闭式解。不必再调用数值优化算法。
KKT条件是对偶问题最优解的必要条件:
除了第一个非负约束以外,其他约束都是根据目标函数推导得到的最优解必须满足的条件,如果违背了这些条件,那得到的解必然不是最优的,目标函数的值会减小。
所以在SMO迭代的两个步骤中,只要中有一个违背了KKT条件,这一轮迭代完成后,目标函数的值必然会增大。Generally speaking,KKT条件违背的程度越大,迭代后的优化效果越明显,增幅越大。
怎样跑的更快?
和梯度下降类似,我们要找到使之优化程度最大的方向(变量)进行优化。所以SMO先选取违背KKT条件程度最大的变量,那么第二个变量应该选择使目标函数值增大最快的变量,但是这个变量怎么找呢?比较各变量优化后对应的目标函数值的变化幅度?这个样子是不行的,复杂度太高了。
SMO使用了一个启发式的方法,当确定了第一个变量后,选择使两个变量对应样本之间最大的变量作为第二个变量。直观来说,更新两个差别很大的变量,比起相似的变量,会带给目标函数更大的变化。间隔的定义也可以借用偏差函数
我们要找的也就是使对于来说使
最大的
很惭愧,只做了一点微小的工作。
References
[1]Platt, John. "Sequential minimal optimization: A fast algorithm for training support vector machines." (1998).
是用来求解出SVM的带约束的优化问题的对偶问题的最优解的二次规划方法,通过求解出对偶问题的最优解,从而得到原始问题的最优解。
这种方法通过不断地将对偶问题的二次规划问题分解成为只有两个变量的二次规划问题,并对子问题求解,通过不断地更新,迭代找出所有约束变量值。
SMO算法的具体步骤如下:
1.确定非线性支持向量机的优化目标:
2.选择出两个变量 ,将优化问题转化成
3.将上面不等式约束变成只对 求解的最优化问题。
求解出的
更新完 重新计算阈值b与误差
输入公式实在太麻烦了。等我有心情了,再把公式补上。
SMO 算法是用来给 SVM 求解的。因此,想要理解 SMO,就必须先理解 SVM 的目标函数式。下面我讲的是软间隔支持向量机,硬间隔支持向量机可以通过把 设置为无穷大来得到。
为了避免讲一大堆与 SMO 不相关的内容,我假设读者已经知道 SVM 原问题的对偶问题:
上述目标函数在约束条件下得到最优解,充分必要条件是找到一组满足 KKT 条件的参数 。此问题的 KKT 条件可以分为四个部分。
第一个部分是对拉格朗日函数求导得到的等式约束:
第二个部分是对偶互补条件,这是 SMO 算法推导的关键:
第三部分是原问题的不等式约束:
第四部分是拉格朗日乘子的约束:
由 与第四部分的约束可以得到下面的约束,这也是对偶问题约束的来源:
以上是 SVM 的目标函数,下面开始讲 SMO。
SMO 算法在在迭代过程中始终保持所有的等式约束成立。同时 SMO 也保持不等式约束 成立(注意,在等式
成立的前提下,
成立也就意味着
成立)。也就是说,SMO 算法在
区间内调整
。初始时 SMO 设置所有的
。注意,此时的参数是不满足 KKT 条件的约束的。
我们知道,KKT 条件被满足是原问题与对偶问题得到最优解的充分必要条件。因此最优化的目标就是将 调整到 KKT 条件被满足的状态。
那么,什么样的参数满足 KKT 条件约束呢?我们从 KKT 条件本身出发来分析一下:
我们知道 ,因此可以将
分为三种情况来分析:
- 第一种情况,
时:
- 由
知道
- 由
知道
,此时
对
无约束,
与
综合起来,我们知道
。
- 这个结论可以从 SVM 的设计上理解:
的松弛量,只有当
,而
。
- 第二种情况,
时:
- 由
,此时由
。
- 由
可知
。
- 这个结论也可以从 SVM 的设计上理解:
- 第三种情况,
时:
- 由
,此时由
- 由
有
。
- 由 SVM 的性质可以知道,当
可以看到,对于我们的优化来说, 和
本身的值并不重要,对于任意一种
的情况,只要对应的
的条件满足,就一定有合法的
与
能让我们取到。
所以现在情况很清楚了,对于每一个 ,如果:
当上面这三条约束对所有的 都成立时,KKT 条件就满足了,我们就得到了最优解。因此我们做 SVM 最优化,目标就是在保持所有等式约束的前提下,使得所有的样本点满足上述条件。
由于不同的 之间相互制约,一次性将所有的
优化到满足 KKT 条件是一个比较难的问题。因此 SMO 算法采用迭代的方法进行优化。
具体地,SMO 每次选择一个违反了 KKT 条件的 ,也就是说,如果:
;
;
那么 SMO 在本轮迭代就可以优化 ,怎么优化呢?我们再回头来看一下我们的最小化目标:
这里首先要理解的是,KKT 约束与上面的最小化目标是一致的,因为上述最优化目标取到最小值的充分必要条件是 KKT 条件被满足。我们刚才把最小化目标函数的目标转化为满足 KKT 条件的约束,因为满足 KKT 条件约束就能最小化目标函数;而现在我们要再将目标转化回来:我们可以通过直接最小化目标函数,使得 KKT 条件约束更完全地被满足。
所以我们现在的任务,就是通过调整 来直接最小化这个目标函数。其余的
全都固定时,上面的这个最优化问题其实就是对于
的一个简单的一元函数优化问题。
不过等等,我们突然注意到约束 。这个约束中的任何一个
单独更改,都会使得约束不满足。因此,只挑选一个
是不够的,我们还需要挑选另一个
与
同步变化,使得
有调整的余地。
的选择比较随意,只要能够使得目标函数下降即可。
我们把除 与
之外的所有变量隐去,可以得到目标
其中 就是所有其他固定的
的和。
接下来,只需要按照 得到
,回代到目标函数中,得到新的目标函数,这个函数太复杂了,我懒得算了...反正可以想得到它是
的二次函数,可以直接对
求导得到最优解。
当然,得出来的最优解不一定符合这个约束
我们接下来只需要选择约束区间内,最接近最优解的那个值就好了(因为二次函数一定是对称的,最越接近最小值的点,二次函数的值越小)。
这就是一步迭代中,我们做的事情。接下来要做的,就是反复迭代选出违反 KKT 约束的量,然后进行这样的优化,直到不再有违反 KKT 条件约束的量,我们就得到了最优解。
SMO 还有一个启发式的优化技巧。就是在 与
的选择过程中,我们可以选择更好的
与
,使得目标函数值尽可能多地下降。
在选择 时,我们选择违反 KKT 条件最严重的样本点
。
在选择 时,我们选择能够使得优化后的目标函数值最小的
。也就是说,我们可以挨个试一下所有的
,分别计算按照这些
与
迭代一步后的目标函数值。然后我们选择结果最小的那个,作为我们最终的选择。
地址:海南省海口市58号 电话:0898-88889999 手机:13988888888
Copyright © 2012-2018 首页-速盈娱乐-注册登录站 ICP备案编号:琼ICP备88889999号


 88889999
88889999

