
速盈注册
算子性能优化 方法介绍
发布时间:2024-05-20 19:48:06 浏览次数:
我们在飞桨内开发并封装了一些优化技巧, 具体如下表所示, 欢迎使用, 也欢迎在使用过程中提出修改建议.
我们推荐结合 OP 的使用场景设计对于的线程配置策略,如下图所示IndexSample OP常用于处理 2 维数据, 因此使用2 维的线程配置策略相对比 1 维配置策略,性能可提升 20%左右。
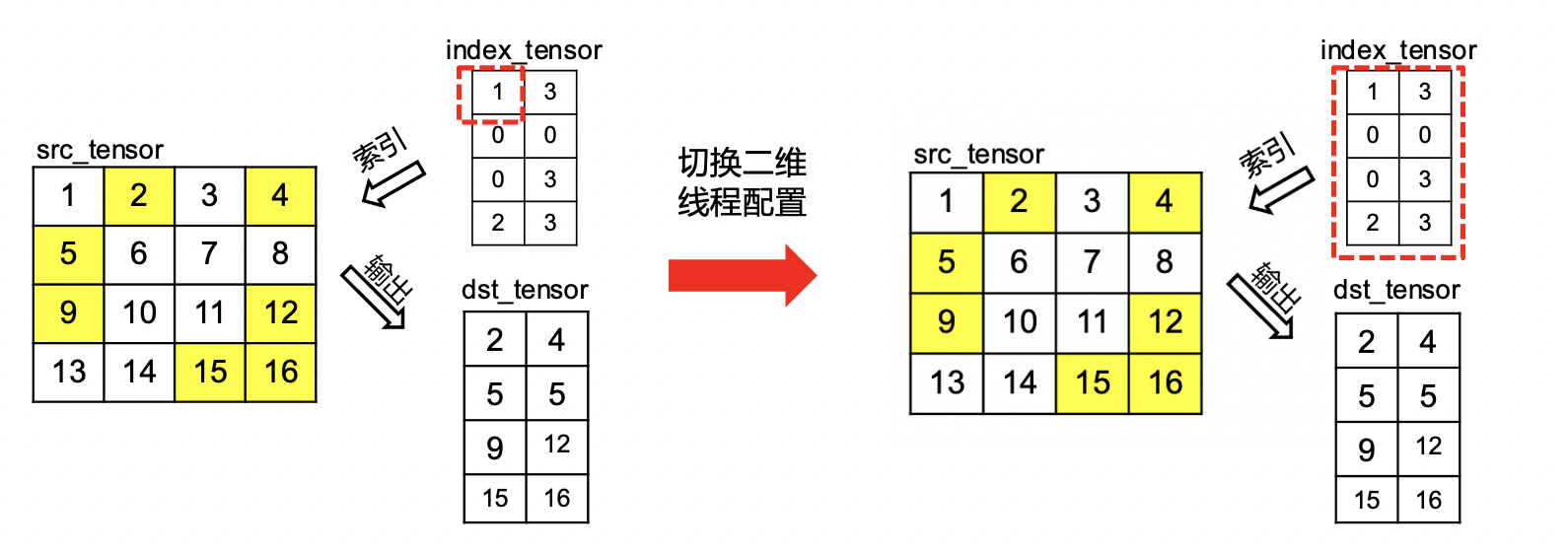
优化 GPU Kernel 中的线程配置策略, 涵盖一维、二维、三维线程配置策略, 目前已经在, , 等 OP 中使用.
飞桨内对上文中提到的Warp 级操作进行了封装, 提供了简易的调用接口, 开发者可调用接口快速获得 Warp 内或者 Block 内的全部数据的求和、最大值、最小值.

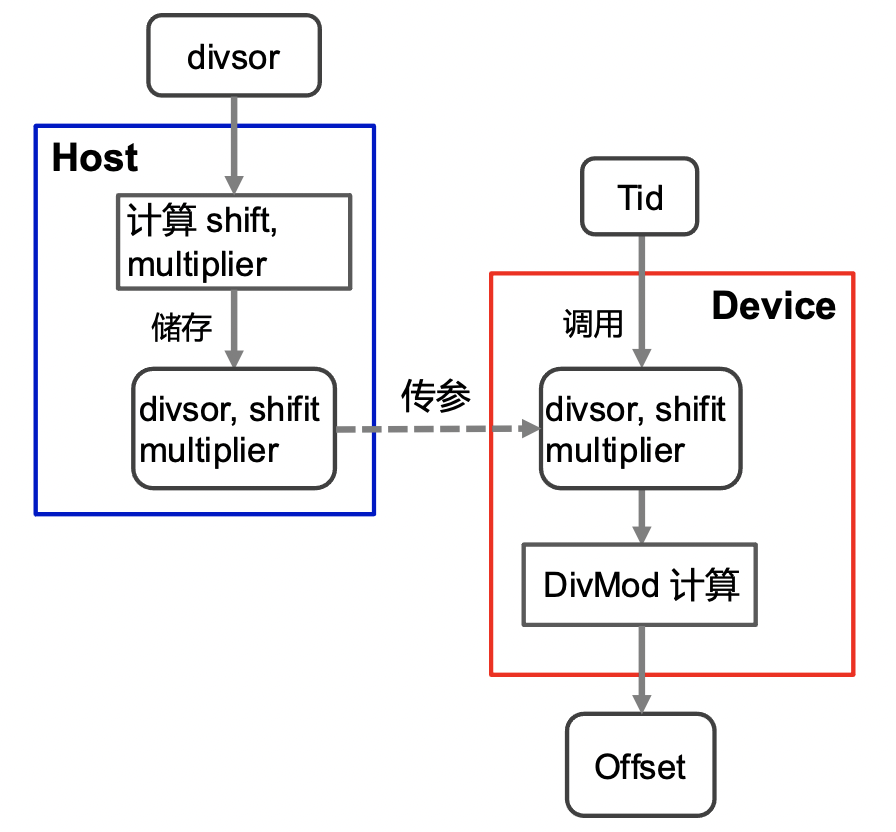
当 GPU Kernel 的索引计算中存在除法或取模操作, 将在导致汇编层面计算开销变大, 我们建议采用快速除法优化这部分的计算开销。飞桨内Pooling OP 采用索引优化计算后, 性能提升 1 倍.
飞桨综合了一系列 GPU Kernel 通用性能优化技巧推出了 Kernel Primitive API,提供高性能的 Block 级 IO 运算和 Compute 运算。使用 Kernel Primitive API 进行 Kernel 开发可以更加专注计算逻辑的实现,在保证性能的同时大幅减少代码量,同时实现了算子计算与硬件解耦,详情见官网Kernel Primitive API, 建议参考案例ElementwiseAdd和Reduce 使用。
我们也鼓励充分挖掘 C++侧的可用优化点, 如使用编译阶段加速指令,编译期自动展循环, 加速运行时循环的执行效率.
案例: Elementwise_add OP 采用模板参数加速循环展开, 性能提升约 5%
struct SameDimsElementwisePrimitiveCaller {
__device__ inline void operator()(Functor func, ArgsT *args, OutT *result) {
#pragma unroll
for (int idx = 0; idx < VecSize; ++idx) {
result[idx] = static_cast<OutT>(Apply(func, args[idx]));
}
}
};
飞桨内置了 cuBLAS, cuDNN, cuSOLVER, Thrust 等一系列第三方库, 若采用这些第三方等高性能计算库能获得显著的性能收益,也欢迎使用。cuBLAS 使用示例见matmul_kernel_impl.h, cuDNN 的使用示例见conv_kernel.cu, cuSOLVER 使用示例见values_vectors_functor.h, Thrust 使用示例见coalesced_kernel.cu.
地址:海南省海口市58号 电话:0898-88889999 手机:13988888888
Copyright © 2012-2018 首页-速盈娱乐-注册登录站 ICP备案编号:琼ICP备88889999号


 88889999
88889999

